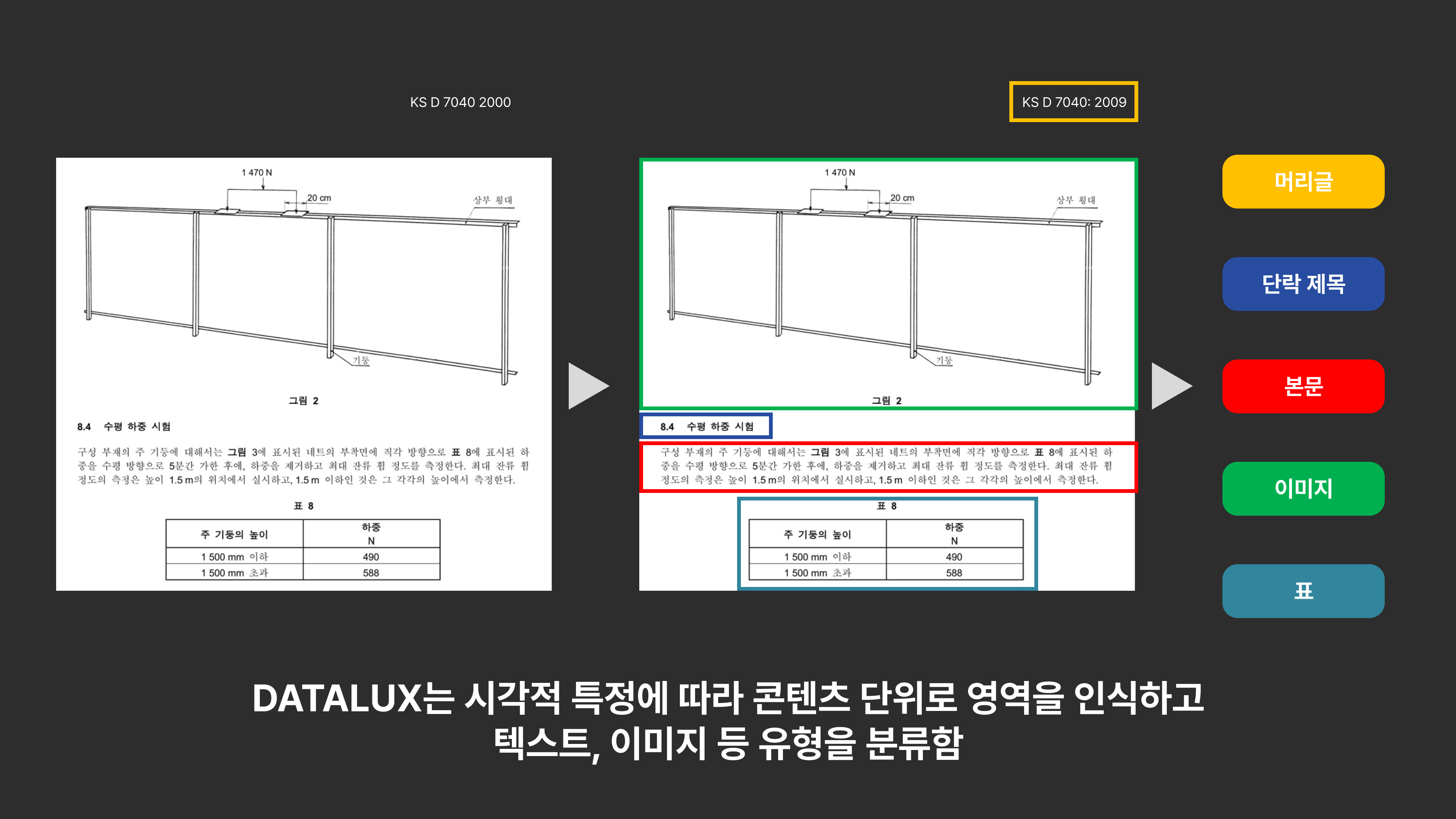
DATALUX는 문서를 콘텐츠 단위로 인식하고 분류하여OCR의 성능을 극대화할 수 있는 고도화된 문서처리 기술입니다.
DATALUX
문서에 OCR을 적용하여 디지털화해본 경험이 있다면 이미지, 주석, 페이지번호 등 각각의 글자 정보가 규칙 없이 뒤섞이며 원문 구조가 깨져 사용하기 불편했던 경험, 다들 한 번씩은 해보셨을 겁니다. 기존 디지털 문서 처리 솔루션은 문자 정보만을 추출기 때문이며, 이 때문에 콘텐츠 활용에 한계가 있을 수밖에 없습니다.
[ 기존 디지털 문서 처리 방식의 한계 ]
원문과 다른 전환 결과
(OCR 한계)
문서 구성(레이아웃) 정보를 배제한 문자 정보 추출
사진 및 그림 내 글자를 인식하여 원문 텍스트 흐름 간섭 발생
非텍스트 콘텐츠 위치 정보 누락
유명무실한 EDMS
(콘텐츠 메타데이터 부족)
콘텐츠 메타데이터 부재로 문서 메타에 따른 필터링만 가능 (문서 제목, 작성자, 작성일 등)
콘텐츠 검색 시 과도한 검색 결과 발생
텍스트(키워드)에 한정된 검색 기능
낮은 AI 확장성
(적재 목적의 저장 형태)
AI 결합 시 전처리 비용 발생
문서 단위의 AI 적용 필요
신규 유형의 문서 발생 시 대응 어려움
혁신적인 멀티모달 AI 기반 문서 처리 솔루션
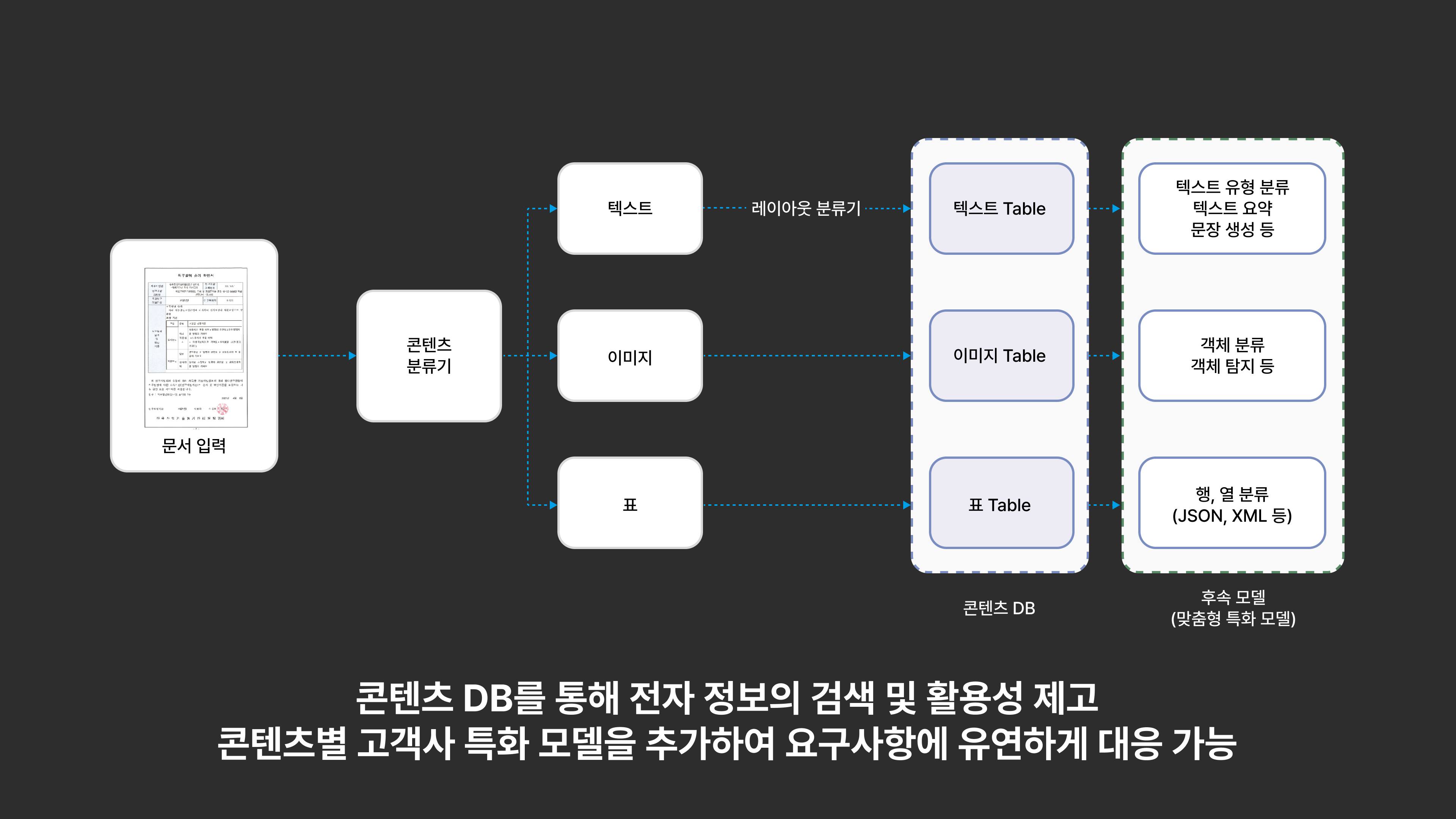
정확한 콘텐츠 추출 및 데이터베이스화
DATALUX는 이미지 처리 모델과 자연어 처리 모델을 결합한 멀티모달 AI 기술을 활용하여 단락, 표, 도면 등 정형화되지 않은 문서에서도 콘텐츠를 정확하게 추출합니다. 또한, 문서의 원문 구조를 그대로 유지하여 정보의 흐름을 보존합니다.
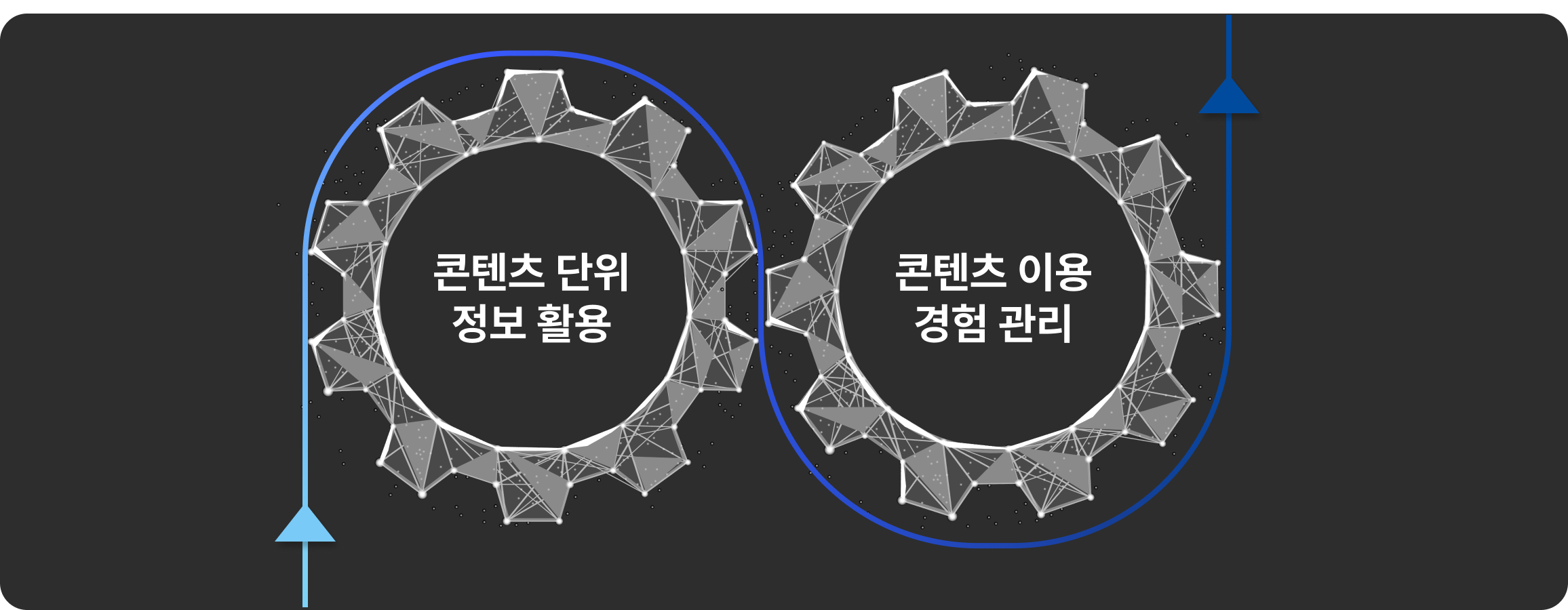
콘텐츠 단위 검색 및 필터링
DATALUX는 추출된 콘텐츠에 제목, 본문의 문서 구조, 콘텐츠 유형 및 좌표 등의 메타데이터를 추가합니다. 이를 통해 사용자는 콘텐츠 단위로 검색 및 필터링을 수행하여 필요한 정보를 빠르고 효율적으로 찾을 수 있습니다.
손쉬운 재구성 및 활용
DATALUX는 메타데이터를 포함하여 추출된 콘텐츠를 HTML 등 원하는 포맷으로 손쉽게 재구성할 수 있도록 지원합니다. 이를 통해 사용자는 추출된 정보를 다양한 목적으로 활용할 수 있습니다.
글자 단위가 아니라 문단으로 이해한다
정확도
96.7%
(Geberal API 기준)
DATALUX는
기업의 잠재력을 무한하게 발휘하고
조직 전체의 실력을 향상시키는
혁신적인 문서 관리 솔루션입니다.
서비스, 제조 및 건설, 공공, 금융, 통신 및 미디어 등 문서 기반 커뮤니케이션이 필수적인 모든 조직은 DATALUX를 통해 Next Level로 넘어갈 수 있습니다.
전사적 정보 활용 능력 강화
DATALUX는 조직 내 정보의 가치를 극대화하여 전사적 정보 활용 능력을 강화합니다.
이를 통해 의사 결정 속도를 높이고 경쟁 우위를 확보할 수 있습니다.
누적된 기록을 데이터로 전환
DATALUX는 멀티모달 AI 기술을 사용하여 정형화되지 않은 문서에서도
정확하게 콘텐츠를 추출하고 데이터베이스화합니다.
이를 통해 조직 내에 잠재되어 있던 지식을 활성화하고 새로운 가치를 창출할 수 있습니다.
맞춤형 정보 검색 포털 구축
DATALUX는 추출된 콘텐츠에 메타데이터를 추가하여
사용자 맞춤형 정보 검색 포털을 구축할 수 있도록 지원합니다.
이를 통해 필요한 정보를 빠르고 효율적으로 찾아낼 수 있습니다.
지식 관리 시스템 구축
DATALUX는 조직 내 지식을 체계적으로 관리하고 공유할 수 있는
지식 관리 시스템 구축을 지원합니다. DATALUX는 콘텐츠 단위로 추출하여 DB화 하기 때문에 파일이 아닌 콘텐츠 단위의 사용 이력을 관리 할 수 있으며, 콘텐츠 유사성 및 사용 이력에 따른 추천 기능 등을 적용 할 수 있어 조직 전체의 생산성과 경쟁력을 향상시킬 수 있습니다.
기존 작업 방식 대비 최대
작업 속도
750 배 향상
(평균 150s/p 대비 0.2s/p)
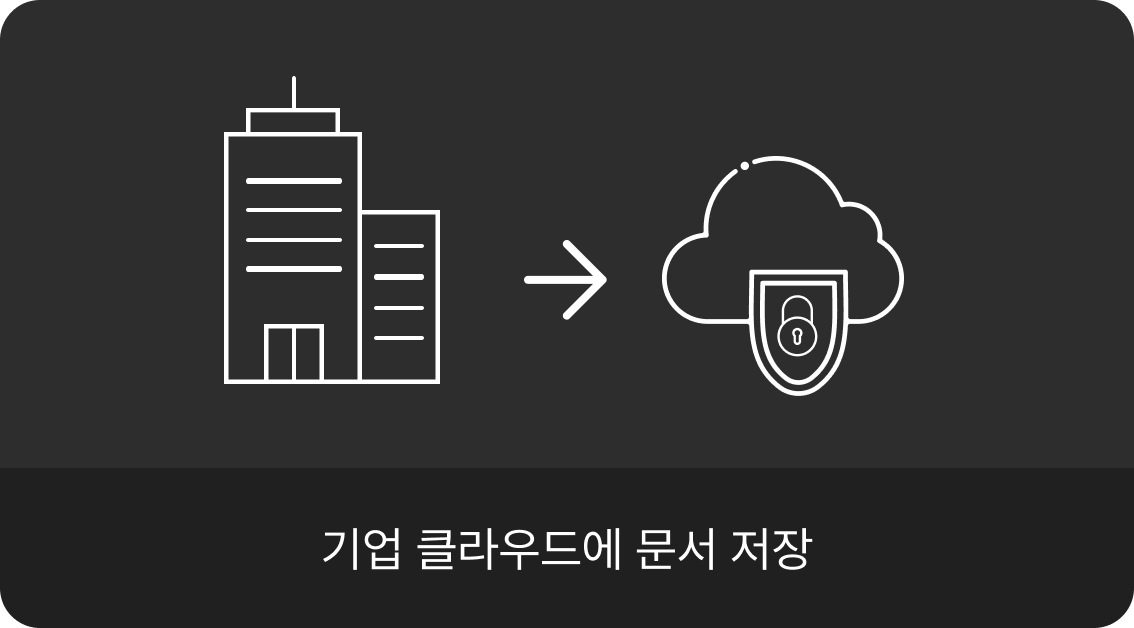
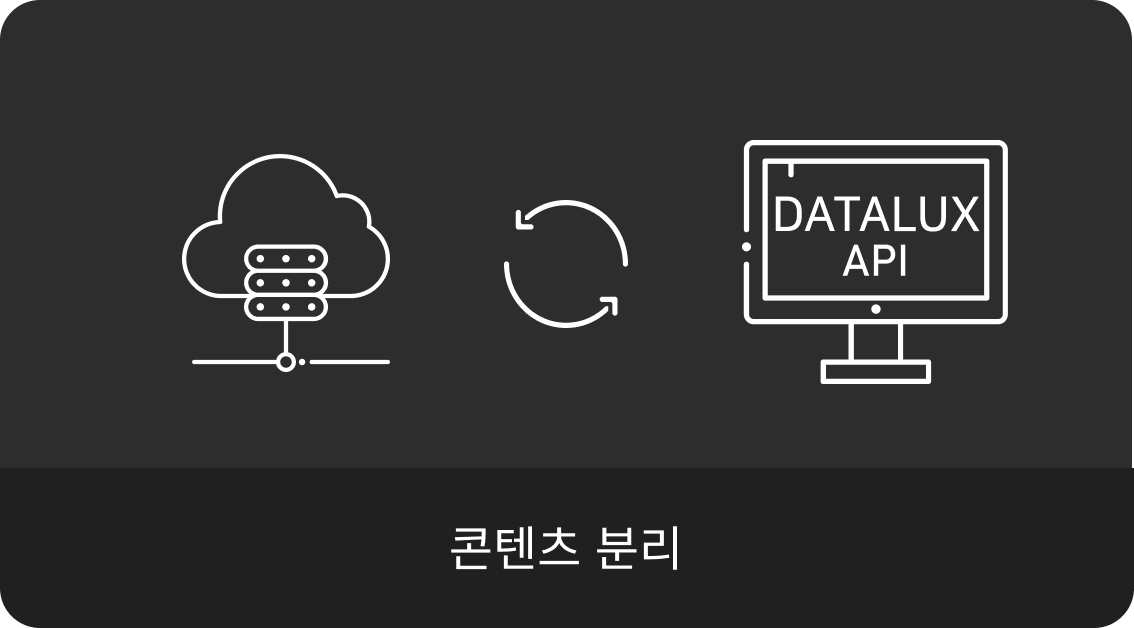
후속 모델 연계
DATALUX는 기업이 보유한 클라우드에 API 형태로 연동하여 활용가능하며, 콘텐츠 추출 후 LLM 기반의 챗봇 모델, 지능형 검색 엔진 등 다양한 형태로 활용 가능합니다.
또한 DATALUX는 표의 경우 json형태로 셀 구조를 저장합니다.
글자 정보 추출, 표 구조 정보 추출, 이미지 품질 향상, 데이터 속성 확장 등
AI 사용을 위한 전처리를 폭넓게 적용한 상태로 데이터베이스가 생성되기 때문에
다양한 AI 모델에 후속 연계하기 용이합니다. 생성형 QA 모델과 결합할 경우 기존 모델이 갖는 검색 범위 문제를 쉽게 해결 할 수 있습니다.
비용 절감을 위한 혁신적 솔루션: DATALUX
DATALUX는 기업의 비용 절감에도 크게 기여합니다. 문서 전환 작업에 필요한 학습 데이터셋 개발 및 디지털 전환 프로젝트 수행으로 직접적인 인건비를 줄이는 동시에, 연구 및 실무 인력의 문서 탐색과 활용 효율이 증가함으로써 간접적인 비용 절감 효과도 누릴 수 있습니다. 또한, DATALUX의 고도화된 문서 처리 기능은 챗봇, LLM 기반 QA 시스템 등의 AI 모델 활용 시 필요한 전처리 작업을 대폭 줄여주어, 큰 규모의 AI 모델을 더 효율적으로 운영할 수 있게 합니다.
평균
92%
비용 절감
(9.7억 원 -> 0.8억 원)
누구보다 앞서있다.
협업 라벨링 솔루션
경쟁력 있는 AI 개발을 위한
LABEL-IT
인공지능의 경쟁력은 데이터셋이 좌우합니다.
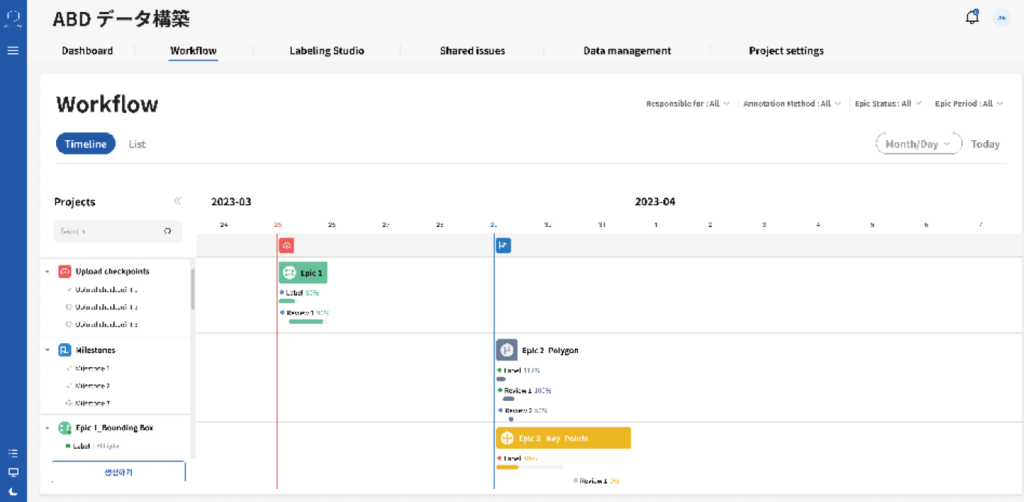
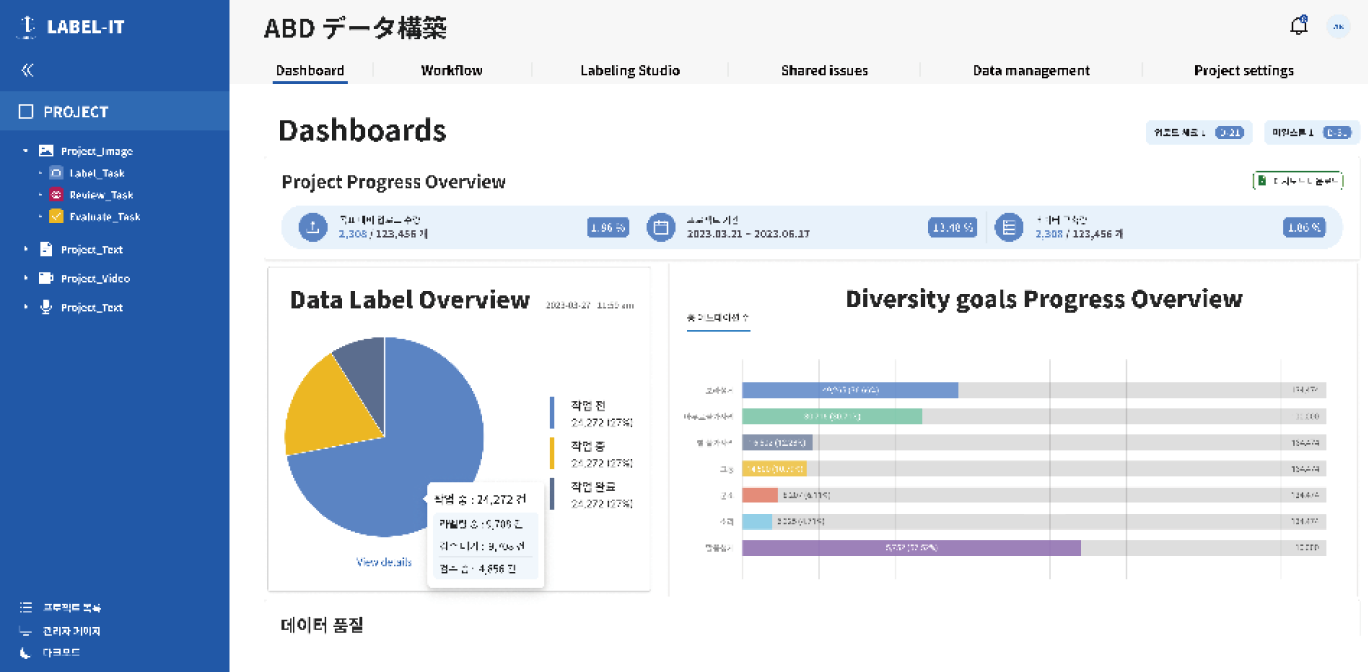
LABEL-IT은 프로젝트 일정 관리부터 품질 검수까지 인공지능 학습셋 구축을 위한 모든 기능을 All-in-one으로 제공합니다.
우리 기업만의 핵심 인공지능 자산인 데이터셋, LABEL-IT과 함께 구축 단계부터 꼼꼼하게 관리하세요.
프로젝트 전반의 업무 진행 현황, 이슈 현황 등을 모니터링하면서 고품질의 학습셋을 구축하세요.
DATALUX는 문서를 콘텐츠 단위로 인식하고 분류하여 OCR의 성능을 극대화할 수 있는 고도화된 문서처리 기술입니다.
DATALUX
문서에 OCR을 적용하여 디지털화해본 경험이 있다면 이미지, 주석, 페이지번호 등 각각의 글자 정보가 규칙 없이 뒤섞이며 원문 구조가 깨져 사용하기 불편했던 경험, 다들 한 번씩은 해보셨을 겁니다. 기존 디지털 문서 처리 솔루션은 문자 정보만을 추출기 때문이며, 이 때문에 콘텐츠 활용에 한계가 있을 수밖에 없습니다.
[ 기존 디지털 문서 처리 방식의 한계 ]
원문과 다른 전환 결과
(OCR 한계)
문서 구성(레이아웃) 정보를 배제한 문자 정보 추출
사진 및 그림 내 글자를 인식하여 원문 텍스트 흐름 간섭 발생
非텍스트 콘텐츠 위치 정보 누락
유명무실한 EDMS
(콘텐츠 메타데이터 부족)
콘텐츠 메타데이터 부재로 문서 메타에 따른 필터링만 가능 (문서 제목, 작성자, 작성일 등)
콘텐츠 검색 시 과도한 검색 결과 발생
텍스트(키워드)에 한정된 검색 기능
낮은 AI 확장성
(적재 목적의 저장 형태)
AI 결합 시 전처리 비용 발생
문서 단위의 AI 적용 필요
신규 유형의 문서 발생 시 대응 어려움
혁신적인 멀티모달 AI 기반 문서 처리 솔루션
정확한 콘텐츠 추출 및 데이터베이스화
DATALUX는 이미지 처리 모델과 자연어 처리 모델을 결합한 멀티모달 AI 기술을 활용하여 단락, 표, 도면 등 정형화되지 않은 문서에서도 콘텐츠를 정확하게 추출합니다. 또한, 문서의 원문 구조를 그대로 유지하여 정보의 흐름을 보존합니다.
콘텐츠 단위 검색 및 필터링
DATALUX는 추출된 콘텐츠에 제목, 본문의 문서 구조, 콘텐츠 유형 및 좌표 등의 메타데이터를 추가합니다. 이를 통해 사용자는 콘텐츠 단위로 검색 및 필터링을 수행하여 필요한 정보를 빠르고 효율적으로 찾을 수 있습니다.
손쉬운 재구성 및 활용
DATALUX는 메타데이터를 포함하여 추출된 콘텐츠를 HTML 등 원하는 포맷으로 손쉽게 재구성할 수 있도록 지원합니다. 이를 통해 사용자는 추출된 정보를 다양한 목적으로 활용할 수 있습니다.
글자 단위가 아니라 문단으로 이해한다
정확도
96.7%
(Geberal API 기준)
DATALUX는
기업의 잠재력을 무한하게 발휘하고
조직 전체의 실력을 향상시키는
혁신적인 문서 관리 솔루션입니다.
서비스, 제조 및 건설, 공공, 금융, 통신 및 미디어 등
문서 기반 커뮤니케이션이 필수적인 모든 조직은 DATALUX를 통해 Next Level로 넘어갈 수 있습니다.
전사적 정보 활용 능력 강화
DATALUX는 조직 내 정보의 가치를 극대화하여 전사적 정보 활용 능력을 강화합니다.
이를 통해 의사 결정 속도를 높이고 경쟁 우위를 확보할 수 있습니다.
누적된 기록을 데이터로 전환
DATALUX는 멀티모달 AI 기술을 사용하여 정형화되지 않은 문서에서도
정확하게 콘텐츠를 추출하고 데이터베이스화합니다.
이를 통해 조직 내에 잠재되어 있던 지식을 활성화하고 새로운 가치를 창출할 수 있습니다.
맞춤형 정보 검색 포털 구축
DATALUX는 추출된 콘텐츠에 메타데이터를 추가하여
사용자 맞춤형 정보 검색 포털을 구축할 수 있도록 지원합니다.
이를 통해 필요한 정보를 빠르고 효율적으로 찾아낼 수 있습니다.
지식 관리 시스템 구축
DATALUX는 조직 내 지식을 체계적으로 관리하고 공유할 수 있는
지식 관리 시스템 구축을 지원합니다. DATALUX는 콘텐츠 단위로 추출하여 DB화 하기 때문에 파일이 아닌 콘텐츠 단위의 사용 이력을 관리 할 수 있으며, 콘텐츠 유사성 및 사용 이력에 따른 추천 기능 등을 적용 할 수 있어 조직 전체의 생산성과 경쟁력을 향상시킬 수 있습니다.
기존 작업 방식 대비 최대
작업 속도
750 배 향상
(평균 150s/p 대비 0.2s/p)
후속 모델 연계
DATALUX는 기업이 보유한 클라우드에 API 형태로 연동하여 활용가능하며,
콘텐츠 추출 후 LLM 기반의 챗봇 모델, 지능형 검색 엔진 등 다양한 형태로 활용 가능합니다.
또한 DATALUX는 표의 경우 json형태로 셀 구조를 저장합니다.
글자 정보 추출, 표 구조 정보 추출, 이미지 품질 향상, 데이터 속성 확장 등
AI 사용을 위한 전처리를 폭넓게 적용한 상태로 데이터베이스가 생성되기 때문에
다양한 AI 모델에 후속 연계하기 용이합니다. 생성형 QA 모델과 결합할 경우 기존 모델이 갖는 검색 범위 문제를 쉽게 해결 할 수 있습니다.
비용 절감을 위한 혁신적 솔루션: DATALUX
DATALUX는 기업의 비용 절감에도 크게 기여합니다. 문서 전환 작업에 필요한 학습 데이터셋 개발 및 디지털 전환 프로젝트 수행으로 직접적인 인건비를 줄이는 동시에, 연구 및 실무 인력의 문서 탐색과 활용 효율이 증가함으로써 간접적인 비용 절감 효과도 누릴 수 있습니다. 또한, DATALUX의 고도화된 문서 처리 기능은 챗봇, LLM 기반 QA 시스템 등의 AI 모델 활용 시 필요한 전처리 작업을 대폭 줄여주어, 큰 규모의 AI 모델을 더 효율적으로 운영할 수 있게 합니다.
평균
92%
비용 절감
(9.7억 원 -> 0.8억 원)
누구보다 앞서있다.
협업 라벨링 솔루션 경쟁력 있는 AI 개발을 위한
LABEL-IT
인공지능의 경쟁력은 데이터셋이 좌우합니다. LABEL-IT은 프로젝트 일정 관리부터 품질 검수까지 인공지능 학습셋 구축을 위한 모든 기능을 All-in-one으로 제공합니다
우리 기업만의 핵심 인공지능 자산인 데이터셋, LABEL-IT과 함께 구축 단계부터 꼼꼼하게 관리하세요. 프로젝트 전반의 업무 진행 현황, 이슈 현황 등을 모니터링하면서 고품질의 학습셋을 구축하세요.