コラボラベリングソリューション
競争力のあるAI開発のための
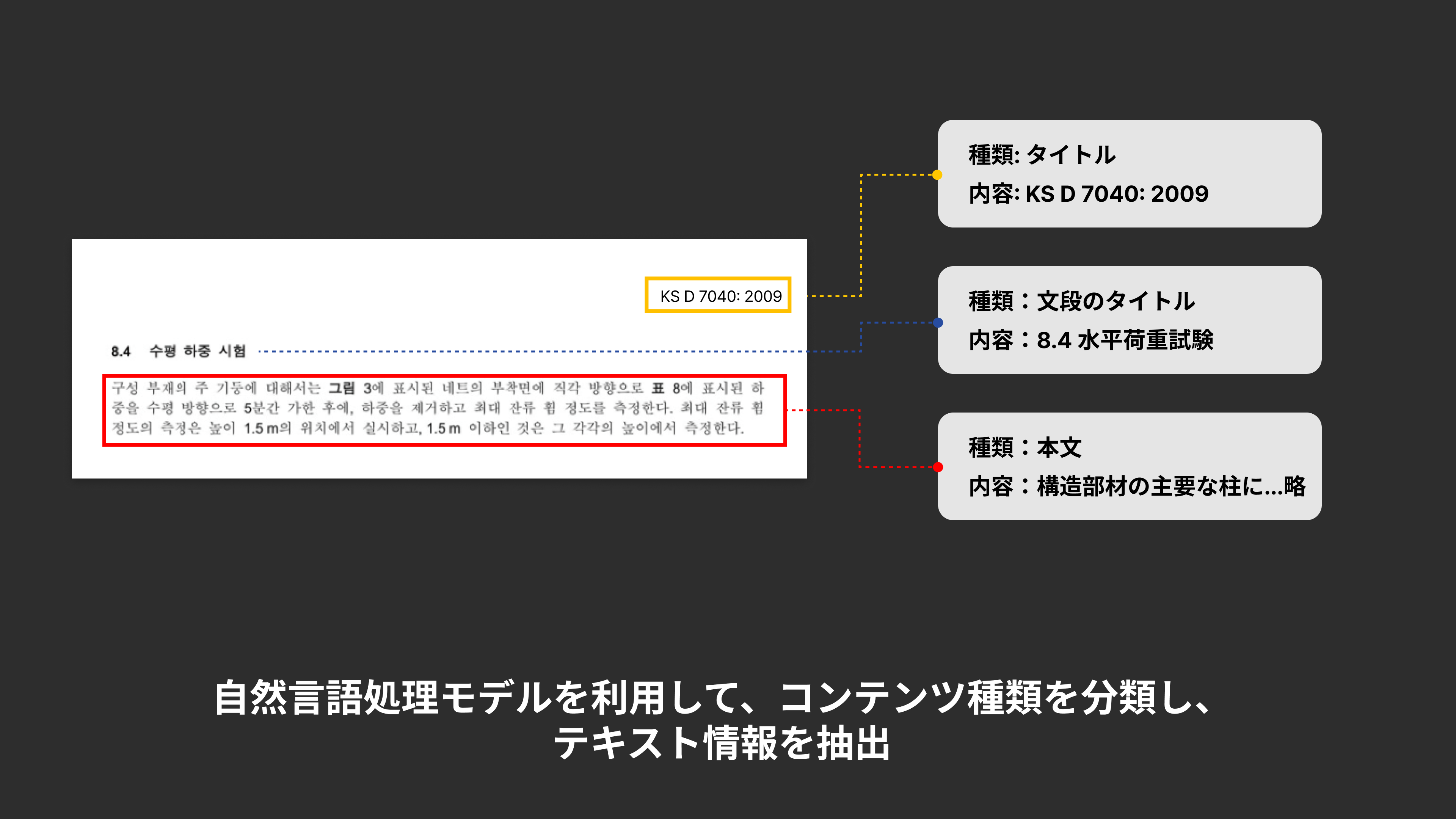
AIの競争力はデータセットに左右されます。
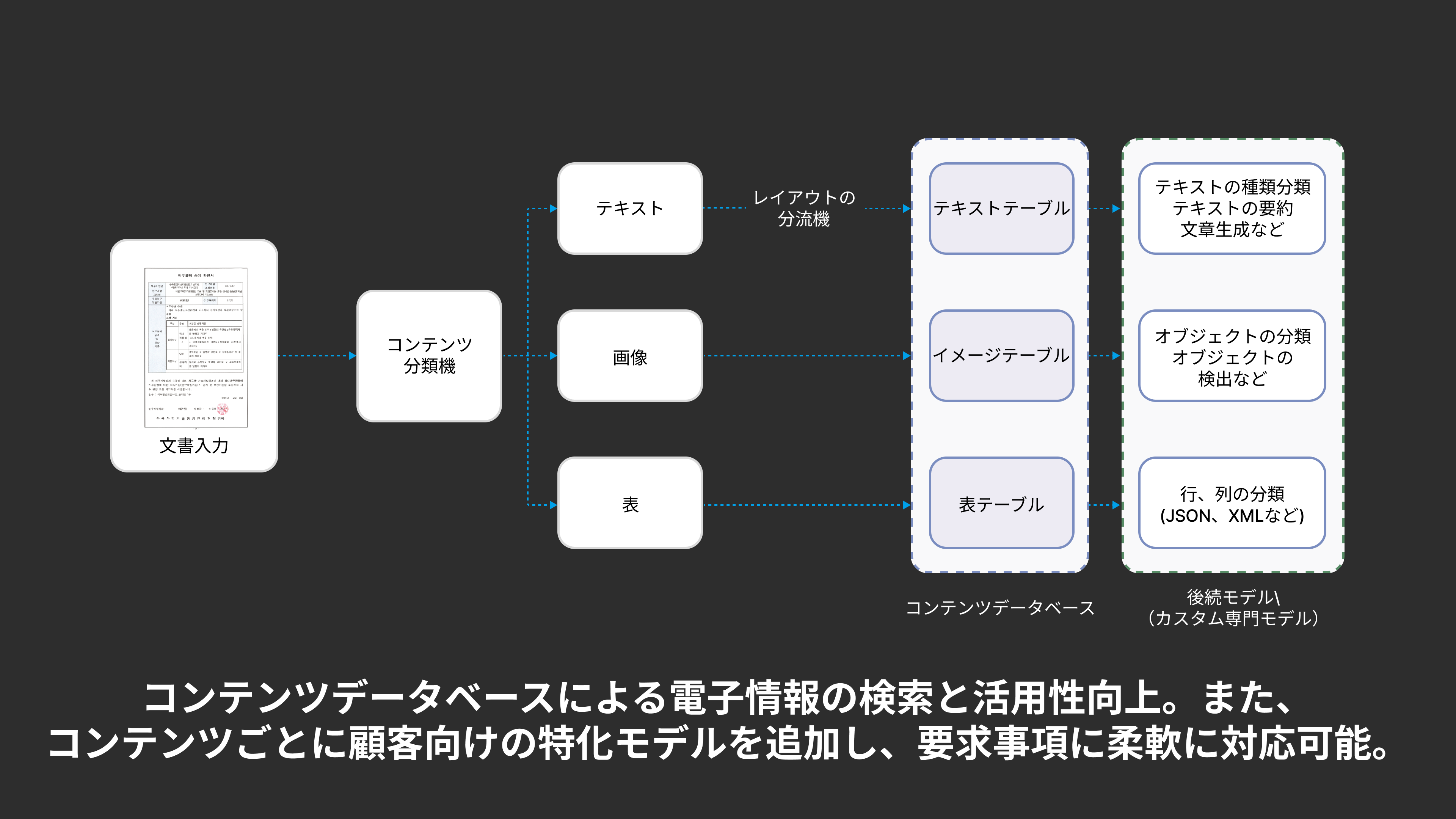
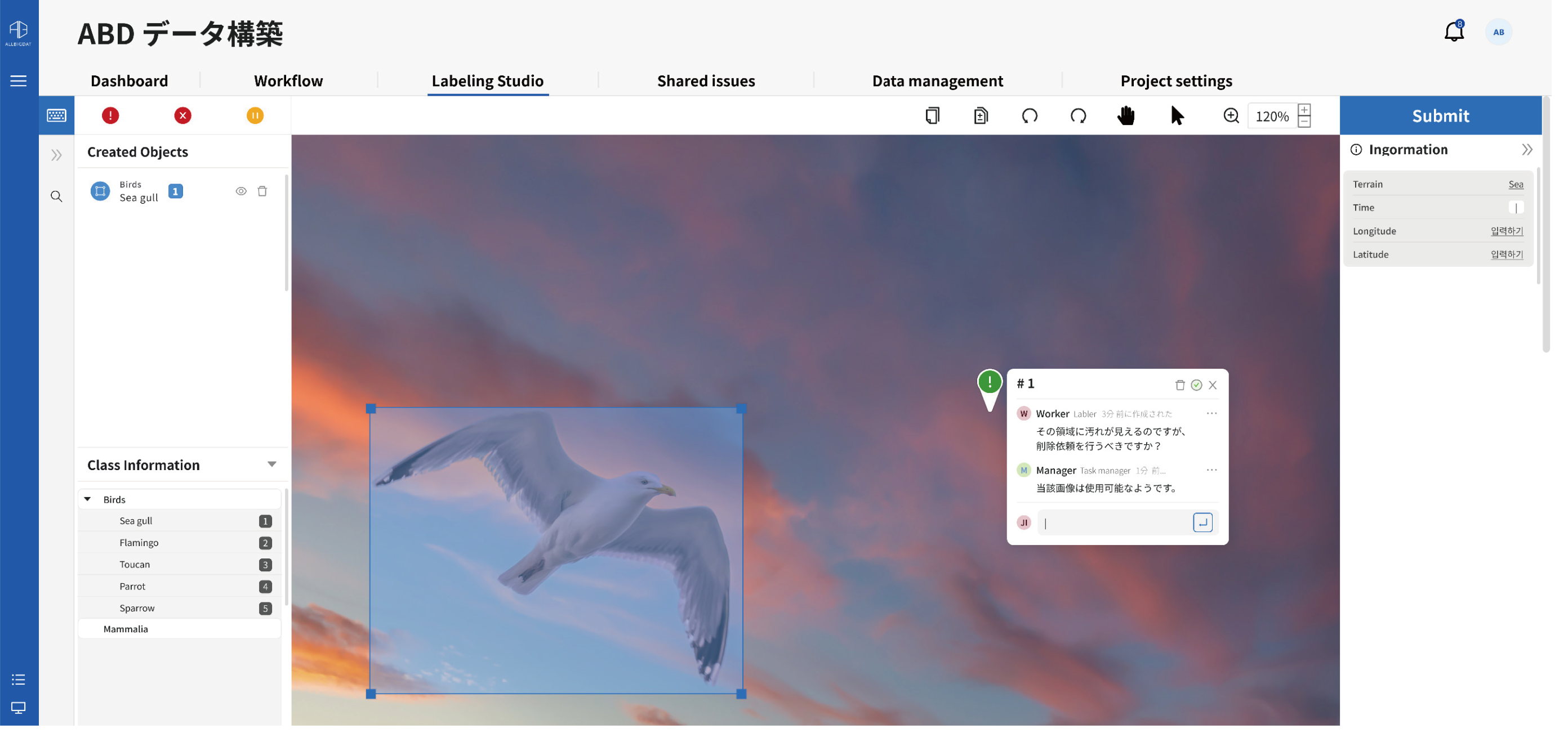
LABEL-ITは、プロジェクトのスケジュール管理から品質検査まで、人工知能の学習データセットの構築に必要なすべての機能をオールインワンで提供します。
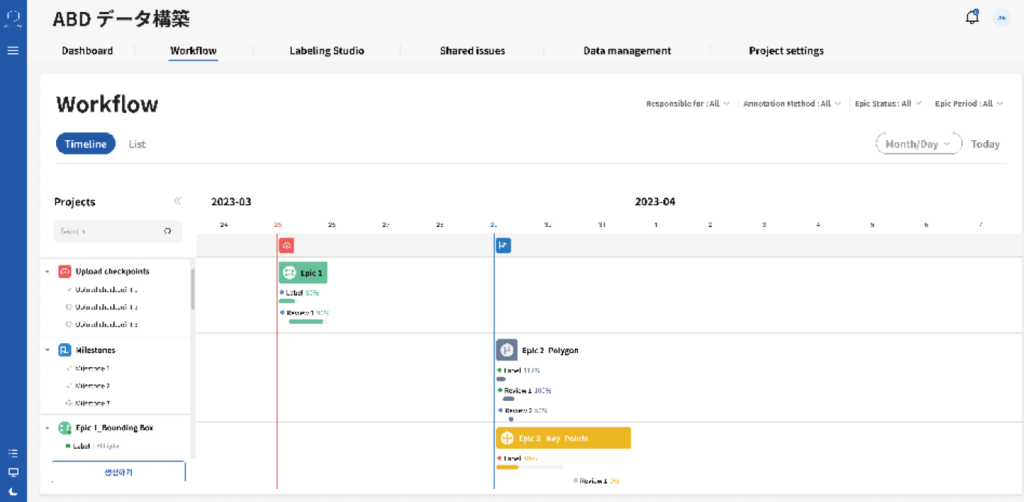
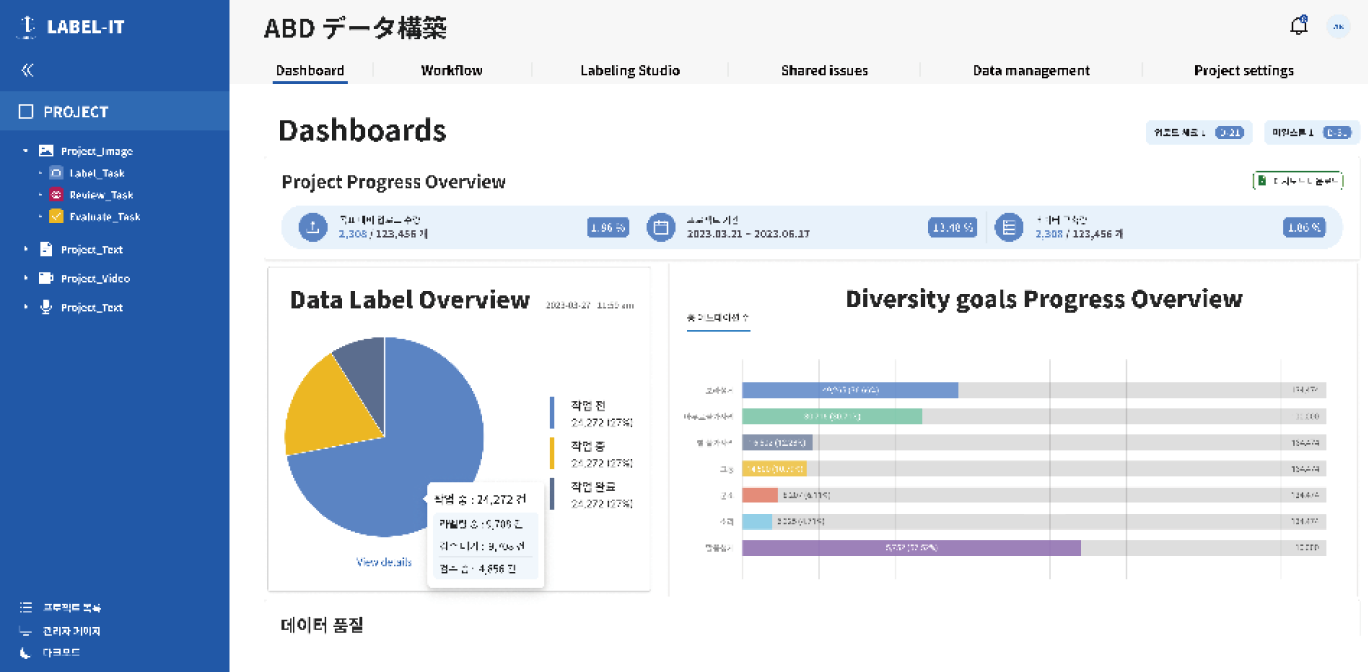
貴社独自のコア資産であるデータセットを、LABEL-ITと共に構築段階から綿密に管理してください。プロジェクト全般の業務進捗状況やイシューの現状などをモニタリングしながら、高品質な学習データセットを構築してください。
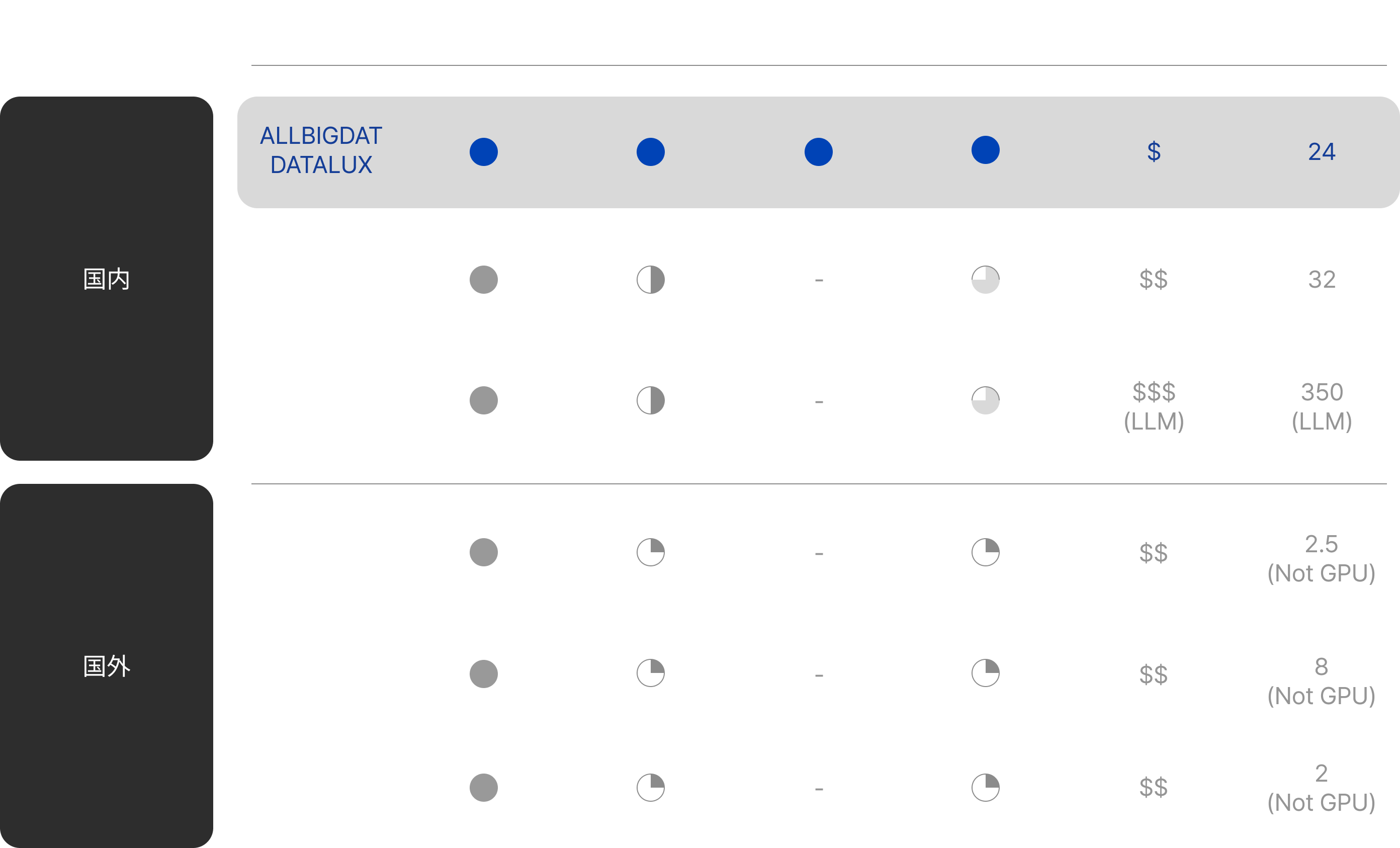
参加企業の役割を指定する機能を搭載した、役割管理機能による企業ごとの成果管理
担当企業、業務タイプなどのフィルタリングによふ直感的なプロジェクト管理